
우리가 이전 포스팅부터 열심히 공부한 신호관련 내용들은 "데이터 통신"이라는 것에서 작은 축에 불과하다.
물리적으로 보내거나 받는 부분을 배운것이고, 이는 Physical Layer(물리 계층)라는 계층에 해당된다.
오늘은 Physical Layer를 거치기 전 Layer인 Data-link Layer(데이터 링크 계층)에 대해 알아보고자 한다.

Node 와 Link
데이터 링크 계층에서 통신은 Node-to-Node라고 표현한다.
둘중에 하나는 분명 데이터를 보내는 쪽을 가리킬거고, 다른 node는 데이터를 받는 쪽을 가리킬것이다.
그리고 데이터는 node들을 연결해주는 link를 통해 전송된다.
겉으로는 별거 아닌 내용이다.
우리가 인터넷으로 유튜브를 본다고 해보자.
유튜브는 인터넷없이는 보이지 않는다.
유튜브 화면을 보내는 쪽과 통신이 안되기 때문이다!
심지어 한국에서 요청한 화면이 미국에 있는 유튜브 서버까지 언제 갔다가 오는지도 모를일이다.
사실 우리가 사용하는 노트북이나 휴대전화로부터 유튜브 영상을 제공하는 구글의 서버까지 선이 하나로 연결된게 아니다.
라푼젤 머리카락처럼 긴 선을 사용하는게 아니라, 일정 길이의 선이 router라는거랑 연결되고, 또 그 router는 다른 라우터랑 연결된다.
따라서 우리가 보낸 영상 요청에 대한 신호는 수많은 라우터와 링크를 거쳐서 서버까지 도달하게 된다.
그래서 중간중간에 존재하는 라우터들도 하나의 node로 간주한다.
LAN(Local Area Network)는 간단하게 생각하면, 집에서 사용하는 와이파이 공유기랑 연결될 수 있는 범위라고 생각할 수 있다.
공유기는 그 위에 있는 라우터에게 신호를 보내고, 그 위의 라우터는 또 다른 라우터에게.. 이게 반복된다.
이걸 node와 link라는걸로 추상화하면, 위 그림의 아래쪽처럼 그래프로 나타낼 수 있다.
위 사진처럼 데이터 링크 계층은 Physical Layer(물리 계층)와 Network Layer(네트워크 계층)사이에 껴있다.
거기서 뭐하는걸까?
데이터 링크 계층은 물리 계층으로부터 데이터를 받아서, 네트워크 계층에게 service를 제공한다.
두 종류의 링크
데이터 링크 계층은 통신 전달되는 수단(medium - 매체 : 유선통신의 케이블, 무선통신에 해당하는 공기 등..)이 사용되는 방식을 제어한다.
뭔소리냐면, 데이터 링크 계층은 medium이 가진 모든 용량(대역폭)을 다 사용할수도있고, 일부만 사용할 수도 있다는 말이다.
이런 medium을 어떻게 제어하는가에 따라 point-to-point link(1 대 1로 연결, 매체의 일부 용량 사용) 나 broadcast link(1 대 전체, 매체의 전체 용량 사용)로 나뉘게 된다.
두 개의 Sublayer
데이터 링크 계층은 그 안에서 두개의 sublayer로 나뉠 수 있다.
하나는 DLC(Data Link Control) 계층이고, 다른 하나는 MAC(Media Access Control) 계층이다.
각 계층은 다른 데이터 링크 계층과 구별되기 위해서 주소(address)를 사용한다.
따라서 MAC주소라는 것을 많이 들어본 분들도 많을거라 생각한다.
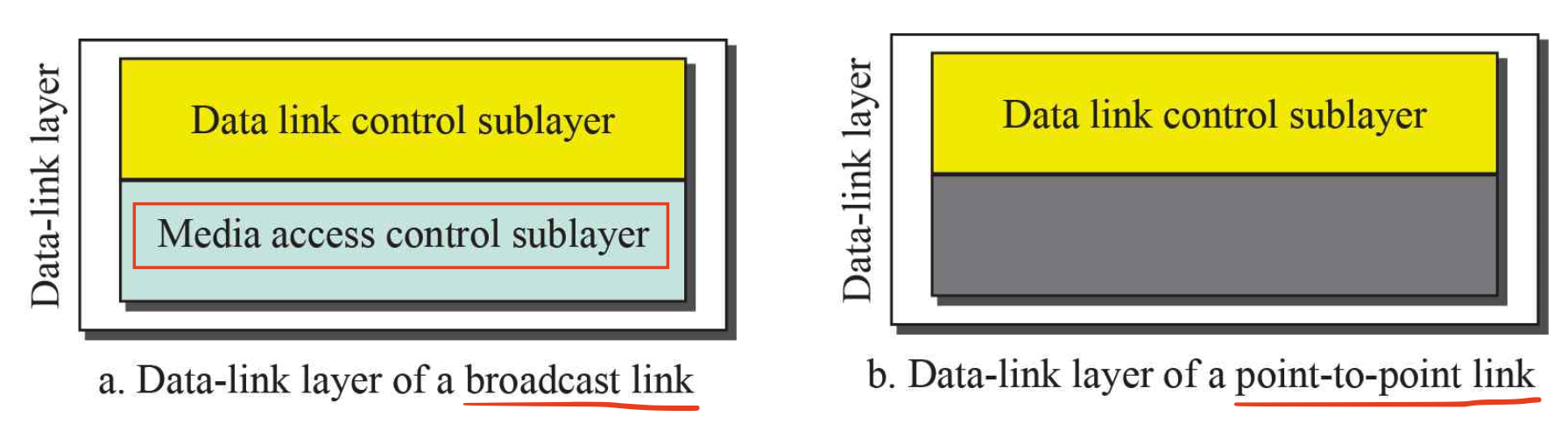
어떤 종류의 링크를 사용하냐에 따라 DLC와 MAC 계층을 모두 사용할 수도 있고, DLC만 사용할 수도 있다.
위 그림을 보면 broadcast link는 둘다 사용하고, point-to-point link는 DLC 계층만 사용한다는 걸 알 수 있다.
Link Layer Address
사실 우리는 IP 주소라는 것만 많이 들어보거나 사용했지, 다른 주소들은 쉽게 듣지도 사용해보지도 못했다.
따라서 다른 주소들이 어떻게 사용되는지 한번 예시를 보자.
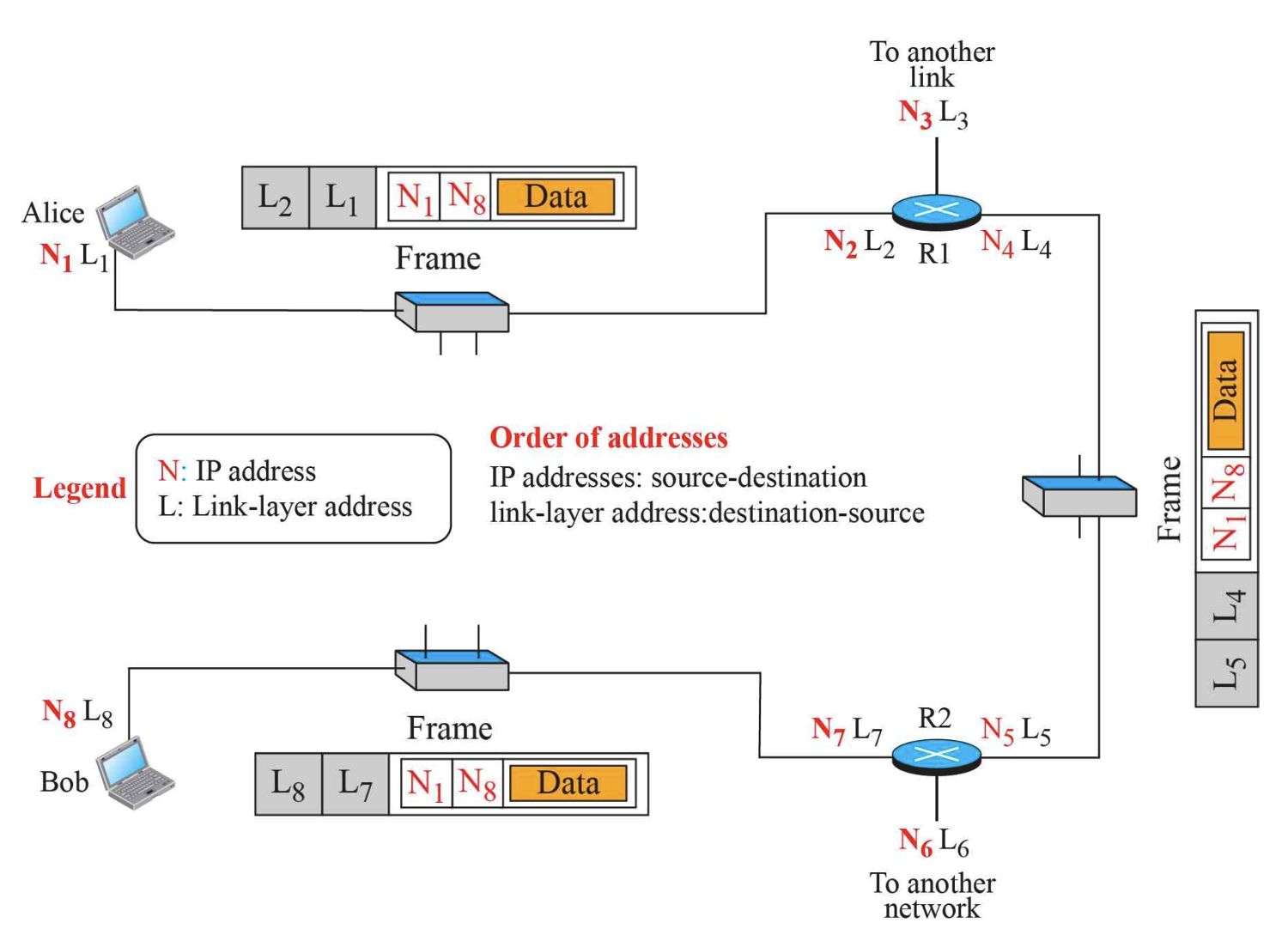
위에서 Frame이라고 되어있는 것은 통신을 통해 이동되는 데이터이다.
단순히 보내려는 정보(Data)만 담고있지 않다.
다른 것들이 무엇인지 살펴보자.
Data 왼쪽의
따라서 어떤 node에서라도 출발지 정보와 도착지 정보 그리고 Data는 바뀌지 않는다.
이때 출발지와 도착지 정보는 IP 주소를 담고있다.
출발지(
이건 데이터 링크 계층의 주소(Link Layer Address)를 의미한다.
위 그림을 잘보면, 각 선마다
Frame의 이동을 잘 보면,
순서대로 왼쪽에 주소가 쌓인다고 생각하면, 왜 회색 박스가 오른쪽은
다른 위치의 Frame도 마찬가지다.
라우터를 만나면, 그동안 달고왔던
라우터는 이 Frame이 어디로 가야하는지 결정하면, 그에 맞는 데이터 링크 계층으로 보낸다.
그래서 맨 왼쪽에 있는 Frame은
첫번째 라우터(
주소의 세가지 종류
열받을 수도 있는데, 주소도 종류가 있다.
Unicast Address
간단하게 말하면 1 대 1 통신을 위한 주소이다.
우리가 사용하는 휴대전화나, 회사들의 서버같이 host라고 불리는 것과 rounter는 unicast address를 가진다.
Multicast Address
1 대 다수에 대한 통신을 위해 만들어졌다.
예를들어 특정 그룹만 지정해서, 메시지를 보내고 싶다면 multicast address를 사용해서 통신을 시도한다.
Broadcast Address
1 대 전체를 위한 통신을 위해 만들어졌다.
마치 방송을 하는 것처럼 본인과 같은 네트워크에 있는 사람들한테 메시지를 보내고 싶다면 broadcast address를 사용한다.
Address Resolution Protocol (ARP)
위에서 살펴봤듯, 우리는 도착지의 IP 주소는 알고있다.
근데 어떤 링크를 거쳐서 가야하는지는 잘 모른다.
목적지가 될 수 있는 모든 곳을 다 뒤져서 도착지의 IP 주소와 같은지 비교할수도 없는 노릇이다.
그래서 나온게 ARP(Address Resolution Protocol)이다.
직역하면 주소 결정 프로토콜이다.
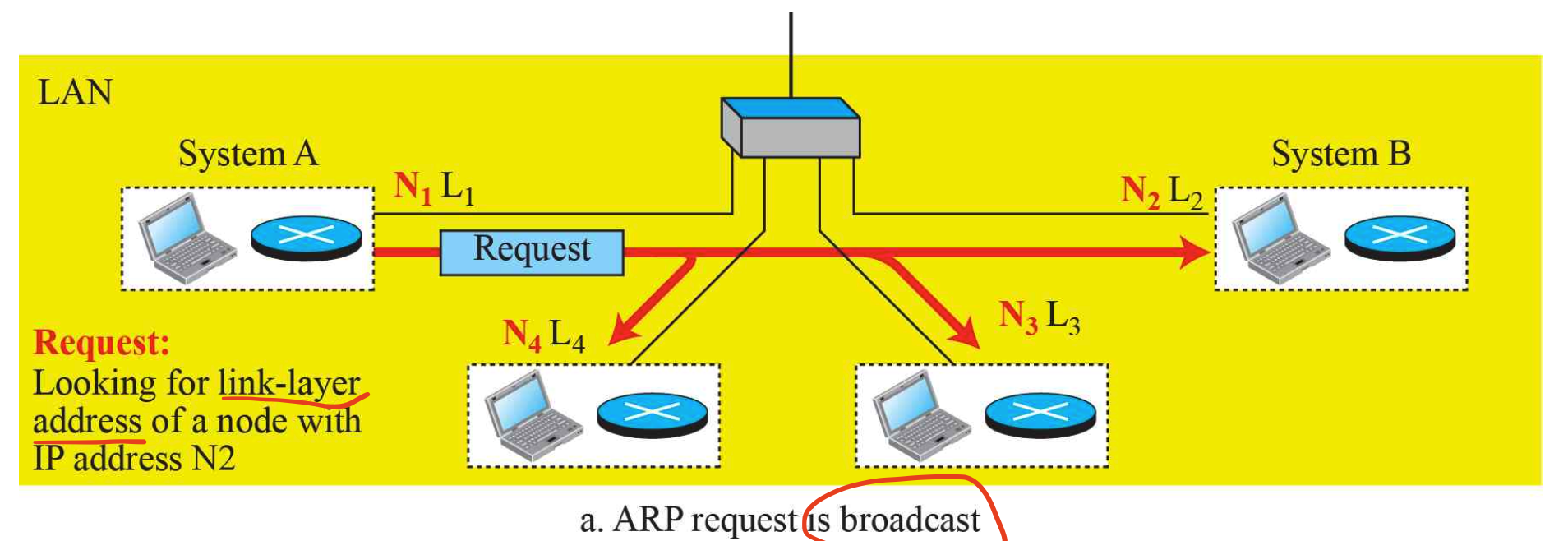
ARP 요청을 보낼때는 broadcast 주소를 통해 보낸다.(모든 곳에 다 전송)
이 ARP 요청을 받은 node들은 본인의 IP 주소와 비교하는 과정을 거친다.
만약 다르다면 해당 요청은 버려진다.
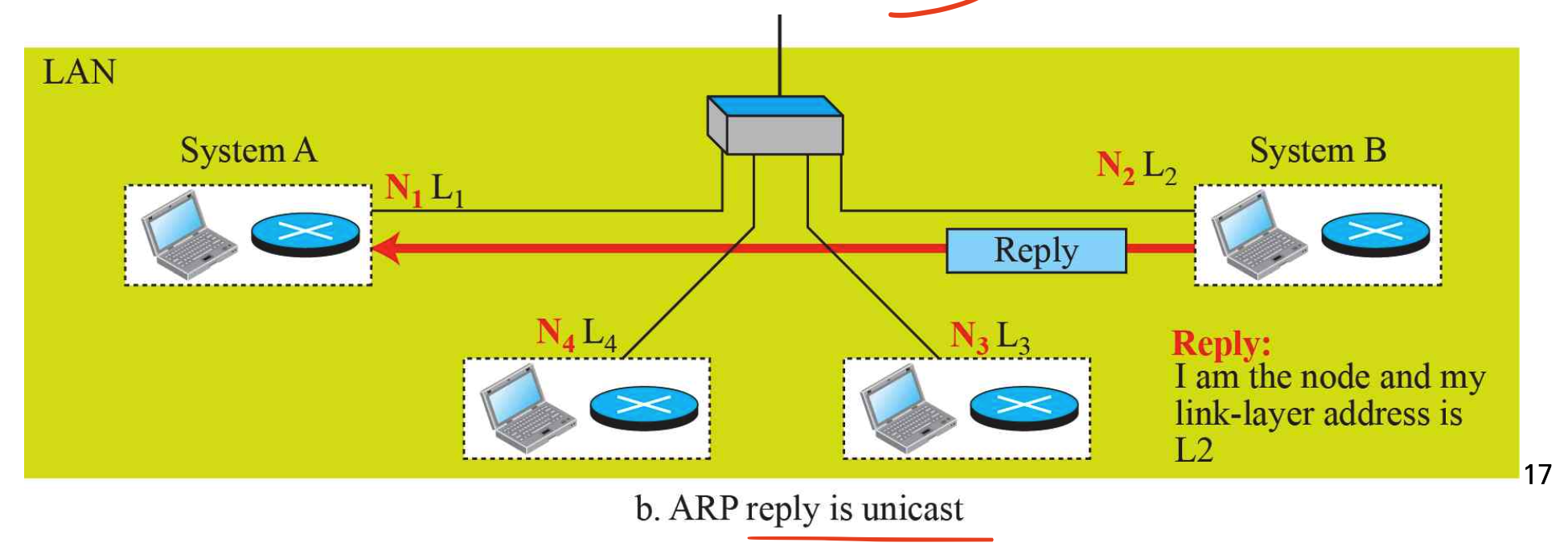
본인의 IP 주소와 같다면, ARP 답장을 unicast로 보낸다.(ARP요청한 node에게만 전송)
ARP Packet
요청이 보내질 때 사용되는 데이터(Packet)은 다음과 같다.
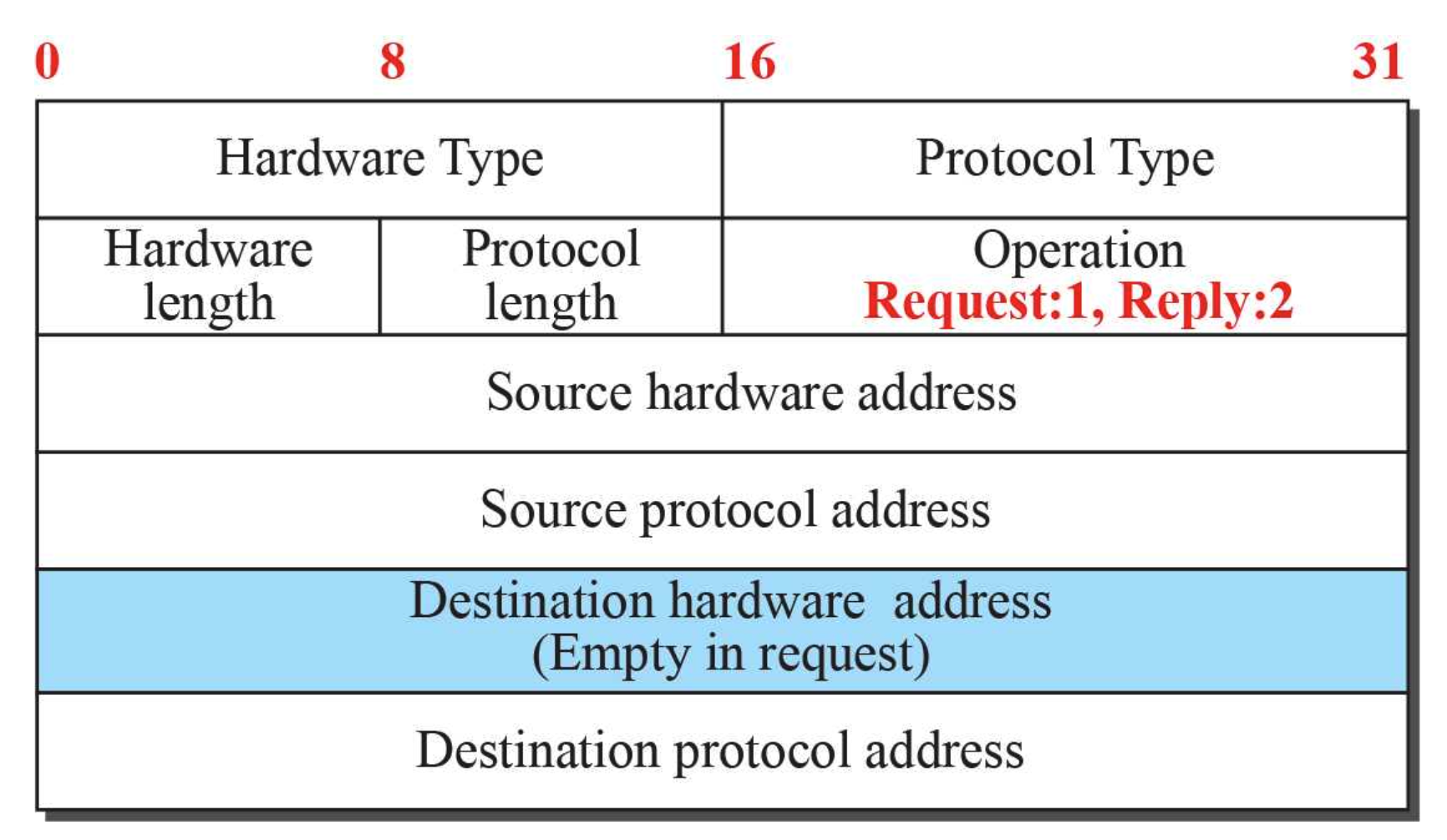
Hardware라는 이름이 붙으면, LAN이나 WAN에서 사용되는 프로토콜이라는 말이고
Protocol 이라는 이름이 붙었으면, Network Layer에서 사용되는 프로토콜이라는 말이다.
LAN이나 WAN에서는 MAC주소를 통해 통신하기 때문에 Network Layer에서 사용하는 IP주소는 사용하지 않는다.
ARP요청을 통해 알아내고싶은건, 도착지 node의 MAC주소이므로(데이터 링크 계층의 주소)
이 부분을 비워놓고 요청(Operation type이 1 : Request)을 보낸다.
답장(Operation type이 2 : Reply)을 보낼때는 답장을 보내는 node에서 데이터가 출발하기 때문에
Source hardware address부분에 우리가 원하는 링크 주소가 들어있게 된다.

A는 B의 IP주소만 알고있는 상태다.
여기서 어떤 링크를 통해 전송되어야 하는 것은 모르므로 ARP요청을 모두(broadcast)에게 보내봐야한다.
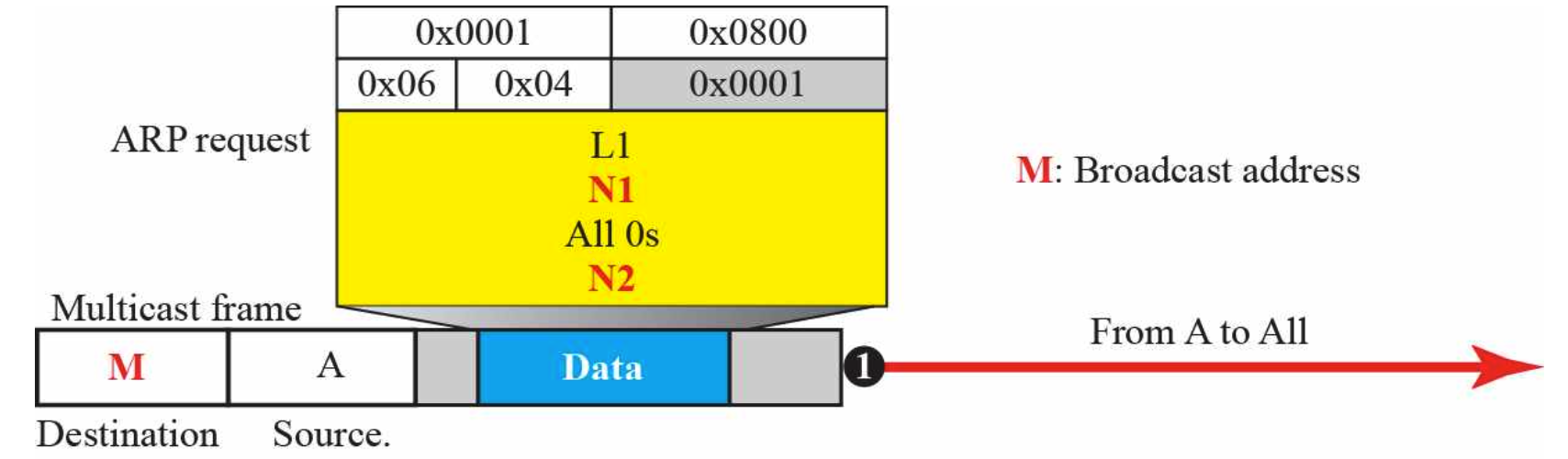
위 그림에서 Destination은 M(Broadcast address)가 되어있고, Source는 A로 되어있다.
또한 Data는 위에서 말한대로 ARP Packet이 들어있으며, 그 내부에 도착지에 대한 링크 주소(MAC address)는 0으로 채워져있다.
또한 요청을 보내기 때문에 회색 네모칸으로 되어있는 Operation type 부분은 Request에 해당하는 1이 채워져있다.
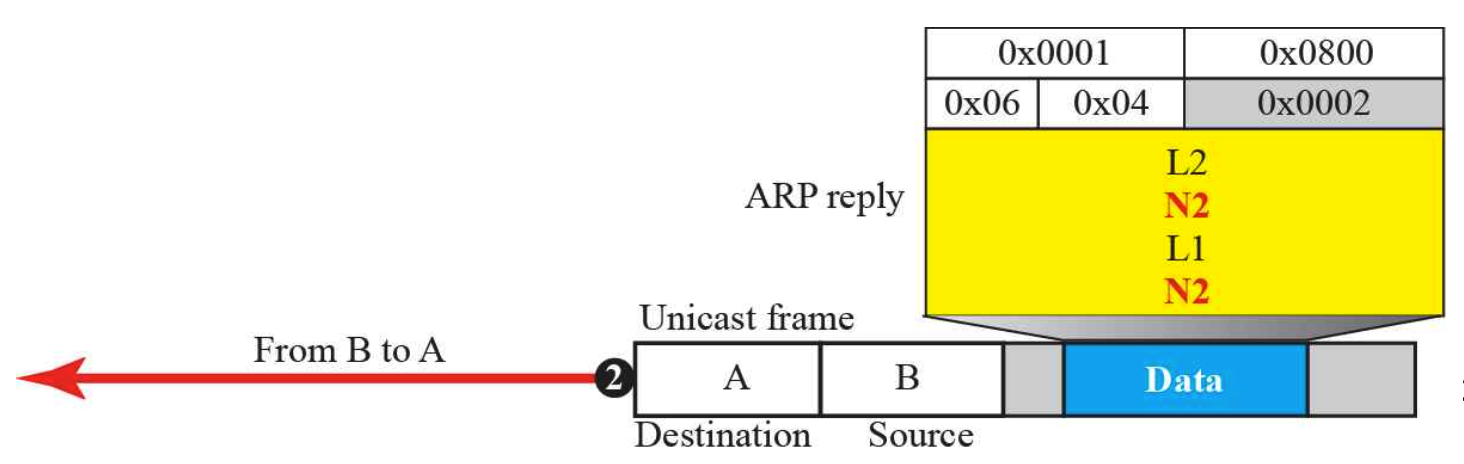
답장을 받을때를 보면, 출발지(Source)는 B이고 도착지(Destination)은 A이다.
또한 링크 주소(MAC address)가 L2라는 것이 Packet의 Source hardware address 부분에 채워져서 오게 된다.
더 자세한 예시를 한번 보자.

네트워크가 위와같이 구성되어있다고 할때, 엘리스는 밥에게 데이터를 보내려고 한다.
엘리스는 밥의 IP주소밖에 모르기 때문에 정확하게 어떤 링크를 통해 보내야하는지 모른다.
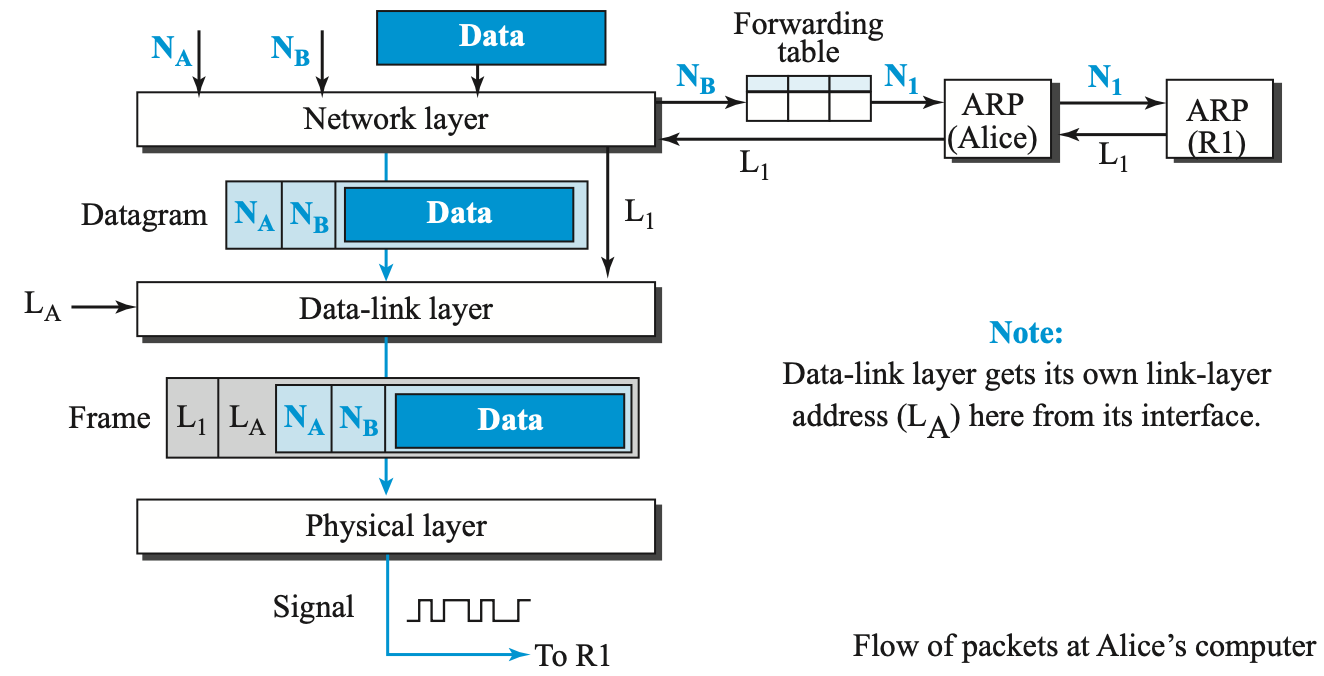
엘리스는 밥의 MAC 주소를 모르기때문에 우선 Forwarding table이라는 곳에 가서
Forwarding table은 라우터(
그럼 엘리스는 받은 IP 주소로 보내기 위한 길을 알기 위해
라우터는 ARP 응답으로 길(링크 주소,
그럼 엘리스는 라우터한테 밥에게 보낼 데이터를 담아서 보내게 된다.
이게 저 위의 사진이 의미하는 이야기이다.
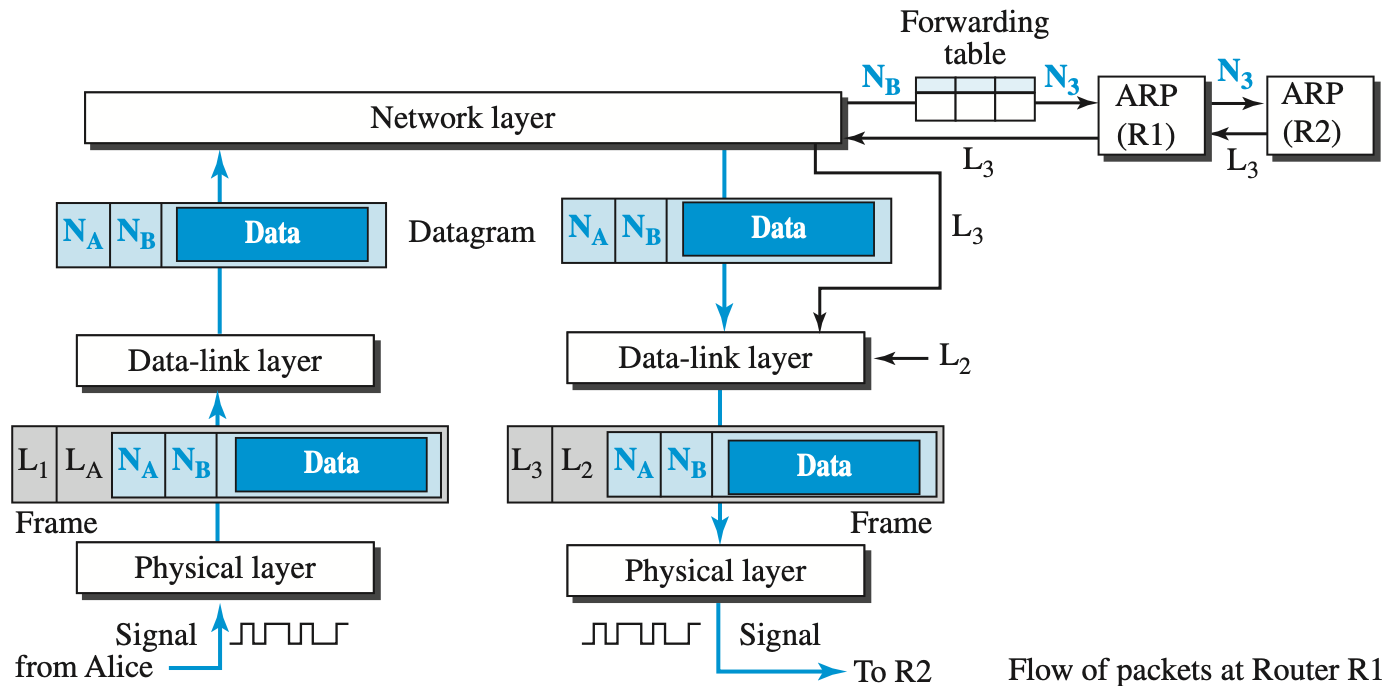
1. Forwarding table은 라우터(
2.
3.
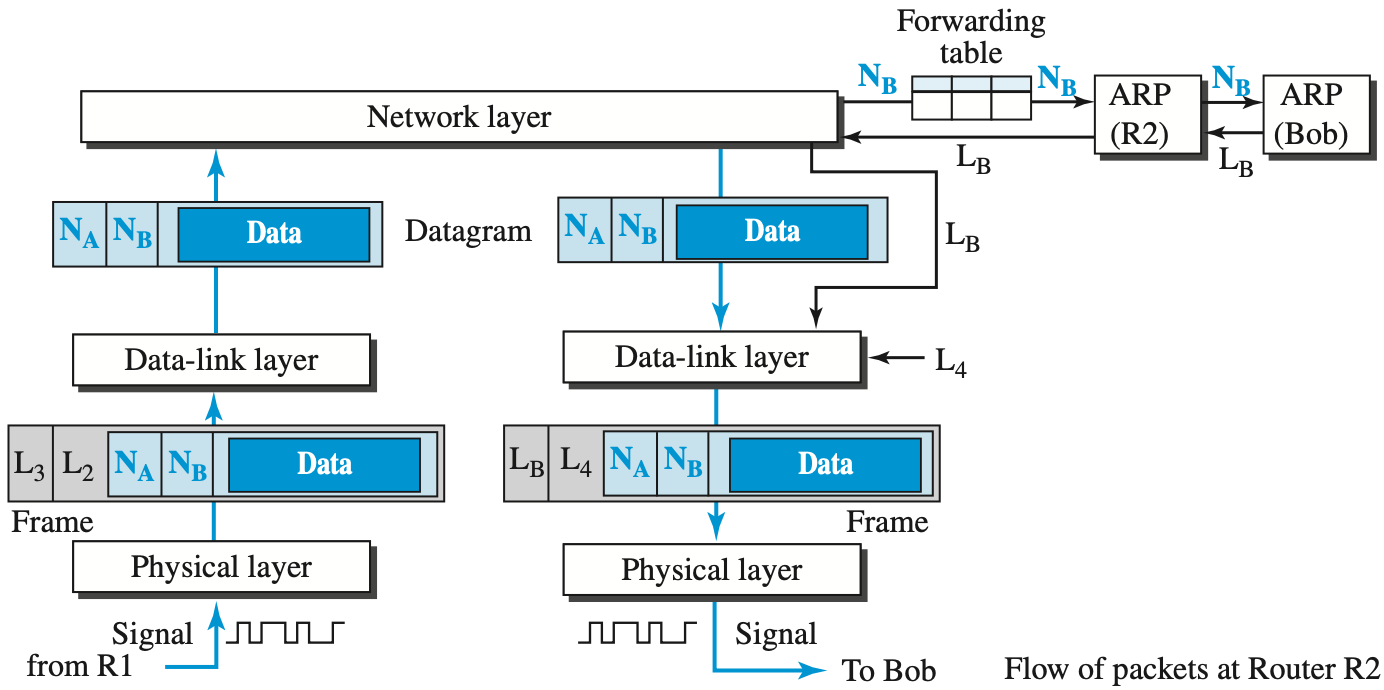
근데 이번엔 밥의 IP 주소가 나와서 결국에는 밥의 링크 주소를 알아낸 후, 성공적으로 엘리스의 데이터를 보내게 된다.
ARP 요청은 밥에게 한번에 갔다가, 다시 엘리스로 응답이 돌아오는 구조가 아니라
다음 노드가 어딘지를 계속 물어보면서 데이터를 보내는 과정중 하나라는 것을 알 수 있다.
Caching
위 ARP 과정을 봤을때, 좀 불편한 부분이 있다.
내용이 좀 힘든거 말고.. 좀 더 효율적으로 할 순 없나? 뭐 이런 생각?
매번 ARP로 주변 node들한테 다 요청 보내는게 너무 비효율적이라는 생각이 든다.
맨 처음 했을때 기억해놨다가, 나중에 또 쓰면 안되나??
그래서 이번에 알아볼게 Caching 이다.
위에서 제시한 해결책 그대로 MAC주소를 기억해놓는다는 말이다.
근데 이걸 계속 기억해놓지는 않는다.
MAC주소는 사실 어떤 장치(지금은 넘어가자)가 만들어질때 부여되는 식별자다.
따라서 이 장치를 갈아끼거나 하면, 저장된 링크로 보내도 받는 곳이 없어진다.
따라서 20분마다 한번씩 저장한걸 없앤다.
ARP에 대해 알아야할 추가적인 정보들
만약 존재하지 않는 목적지에 대해 ARP요청을 보내게 되면 어떡하지?
--> 일정 시간이 지나도 응답이 없으면, 그냥 포기한다..
만약 본인한테 ARP요청을 보내면 어떡하지?
--> 정상적인 요청으로 응답도 잘 온다. IP 주소를 잘 받았는지 확인하는 용도로 쓰인다.
만약 요청하지도 않은 ARP응답을 받으면 어떡하지?
--> Caching된 정보를 덮어씌운다(!!). 이를 ARP poisioning이라고 하고, static ARP를 사용하거나, 암호화를 해서 피할 수 있다.
'CS > 데이터 통신' 카테고리의 다른 글
| [데이터 통신] Data Link Control(DLC) (4) | 2023.05.19 |
|---|---|
| [데이터 통신] Error Detection 과 Correction (4) | 2023.04.19 |
| [데이터 통신] Spread Spectrum (0) | 2023.04.12 |
| [데이터 통신] Multiplexing (0) | 2023.04.12 |
| [데이터 통신] Analog-to-Analog 변환에 대해 (1) | 2023.04.12 |