서론
앞으로 node라는 말을 station이라고 바꿔서 말할 예정이다.
따라서 이후 내용에서 station이라고 하면, node라고 생각하자.
Media라고 하면, 두 station를 연결하는 link(선), 그 자체를 말한다.
즉, 두 station은 유선으로 연결 되어있을 수도 있고, 무선으로 연결 되어있을 수도 있다.
이 선 자체에 접근하는 이유는 당연히 뭔가 데이터를 전송하거나 받는 행위를 하기 위해서 그렇다.
한 단어로 말하자면, 통신! 이다.
이 선에 접근하는 것(Media Access)을 제어(Control)하는 이유는 제어하지 않으면 뭔가 안 좋은 일이 일어나기 때문이다.
예를 들어보자.

위와같이 구성된 네트워크가 존재한다고 할때, 오른쪽 3대의 컴퓨터가 서로 통신을 위해 데이터를 주고 받는다고 생각해보자.
A라는 컴퓨터가 B라는 컴퓨터에게 데이터를 보내는 동시에
C라는 컴퓨터가 B라는 컴퓨터에게 데이터를 보낸다면
A와 C는 동시에 하나의 선으로 통신을 보낸다.
아무 일 없으면 좋겠지만, 아쉽게도 충돌(Collision)이 일어난다.
충돌이 일어나면, B는 어떤 데이터라도 제대로 받지 못하게 된다.
따라서 서로 순서를 정하고, 한번에 하나의 데이터만 전송되도록 제어해야하는 상황이 나와버린다.
그래서 media access control 이라는게 존재한다.
즉, link를 공유하는 상황에서 서로 원활이 통신하기 위해 나온 것이 MAC이다.
Media access 를 위한 protocol은 특징에 따라 3가지로 분류된다.
1. Controlled-access protocols
2. Random-access protocols
3. Channelization protocols
하나씩 탐구해보자. 화이팅.
Controlled-access Protocols
Controlled access, 제어된 접근이라는 말로 이미 접근 자체가 제어가 이루어지고 있다는 말이다.
특징은 다음과 같다.
특정 station이 다른 station에게 데이터를 전송하려면, 검증을 꼭 받아야한다.
이런 특징을 갖는 방식은 총 3가지로
1. Reservation
2. Polling
3. Token passing
이다.
Reservation
데이터를 보내기 전, 예약(Reservation)을 해야하는 방식이다.
시간을 분할하고, 각 분할된 시간(time interval)들 중 하나에 데이터를 전송하겠다고 예약한다.
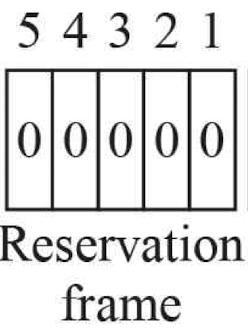
5개의 station이 존재하는 상황이다.
1번~5번 station에 대해 보낼 데이터가 생기면, 위 reservation frame에서 맞는 위치의 값을 1로 바꾼다(reservation).
매 시간마다, 1~5번 순서로 reservation frame의 값들을 읽고
값이 1인 부분이 있으면 그에 대응하는 station에서 데이터를 받은 후, 보낸다.

오른쪽에서 왼쪽 방향으로 진행된다고 하자.
먼저 1, 3, 4번 station이 예약을 걸어놨고, 1~5번 순서대로 읽어서 보내기 때문에 1, 3, 4 순서대로 데이터를 보낸다.
이후 두번째 interval에서는 1번 station만 예약을 걸었기 때문에 1번만 보내고 끝난다.
이런식으로 예약 후, 보내기 과정이 이루어진다면 충돌은 절대로 발생할 수 없다.
Polling
Polling은 Primary station 과 Secondary station 이 존재한다.
Primary station은 link를 제어하고, secondary station은 지시 (instruction)에 따른다.
Primary station은 secondary station에게 크게 두가지를 지시한다.
1. select
2. poll
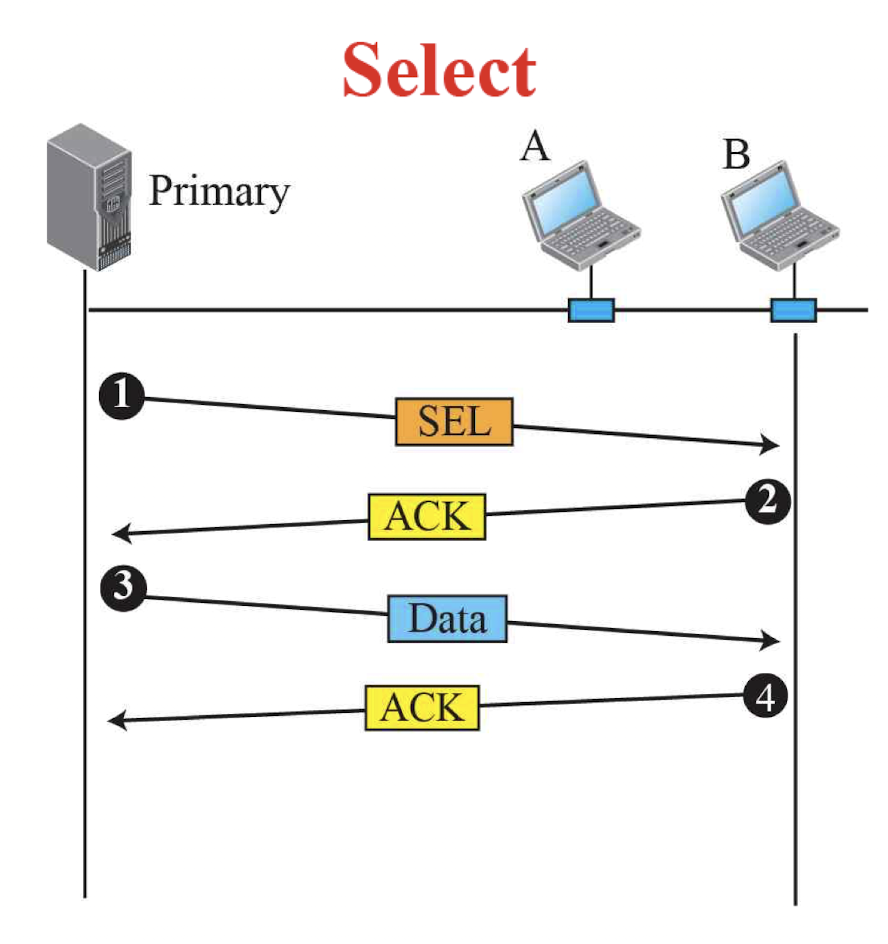
위 사진은 primary station이 특정 secondary station을 골라서(select) 데이터를 보낼 것이라고하는 과정을 보인다.
Primary station의 지시(instruction)에 대해
Secondary station은 데이터를 받을 수 있는 상태라면 ACK, 받을 수 있는 상태가 아니라면 NAK를 보낸다.
위의 경우 B는 받을 수 있는 상태이기 때문에 ACK를 primary station에게 보냈고,
이를 확인한 primary station은 데이터를 보낸다.
Secondary station은 잘 받았기 때문에 ACK를 보낸다.

위 사진은 primary station이 특정 secondary station에게 데이터를 받는(poll) 과정을 보인다.
Select와 마찬가지로 데이터를 보낼 수 있는 상황이면 ACK, 아니면 NAK를 보낸다.
그리고 primary도 데이터가 잘 왔으면 ACK를 보낸다.
Token Passing
이름에서 알 수 있듯, 토큰을 넘기는 방식이다.
토큰을 가진 station만 데이터를 전송할 수 있다.
이때, token passing 방식을 사용하는 네트워크는 논리적으로 ring 형태를 띈다.
무슨 말이냐면, 네트워크를 bus나 star방식으로 구성했어도, token은 원의 형태로 공평하게 주어진다.

총 4개의 방식이 존재한다.
a. 물리적으로 ring을 구성했다.
b. 양방향으로 ring을 구성했다.
c. 물리적으로는 bus 형태지만, 토큰은 ring형태로 빙글빙글 돈다.
d. 물리적으로는 star 형태지만, 마찬가지로 토큰이 빙글빙글 돈다.
토큰을 가진 station만 데이터를 전송할 수 있으므로, 문제가 생기지 않는다.
Random-access Protocols
Station들이 무작위로 medium(매질이라는 뜻이며, link와 같음)에 접근해서 데이터를 보내는 방식이다.
즉, 모든 station이 데이터를 보내려고 하는 상황이 발생하고, 이를 제어하는 것은 오직 정의된 protocol 밖에 없다.
Protocol은 어떤 station이 데이터를 보내도록 결정할때, medium이 사용중인지(busy), 아닌지(idle)를 보고 결정한다.
다음 4가지 방식을 소개한다.
1. ALOHA
2. CSMA
3. CSMA/CD
4. CSMA/CA
ALOHA
이름부터 좀 어그로를 끄는 경향이 없지 않은데, 웃긴건 진짜 하와이에서 만든 방식이다!
라디오같은 무선 LAN에서 사용되며, medium이 공유되는 환경이어야한다.
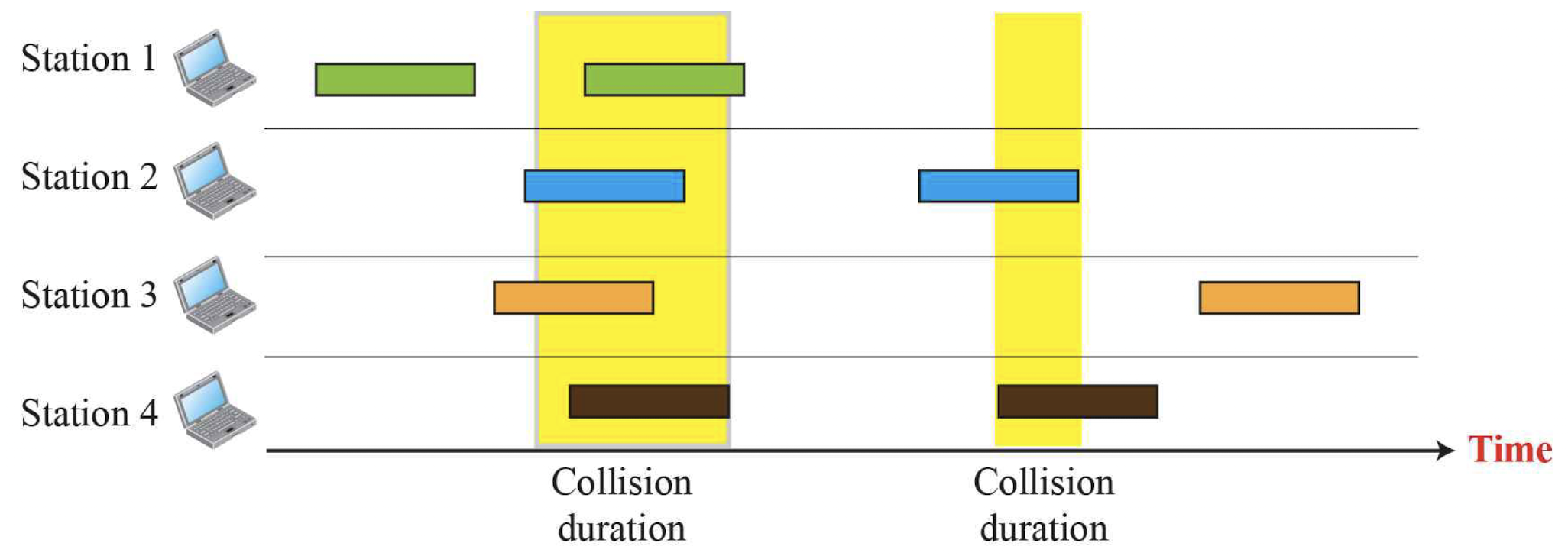
위 모습은 ALOHA 방식이 동작하는 모습이다.
무식하게 막 보내서 충돌(collision)이 일어나는 frame이 많다는 것을 알 수 있다.
될때까지 던진다는 마인드.

어떤 데이터를 성공적으로 보냈다라는 것은, 보낸 데이터에 대한 ACK를 성공적으로 받았다는 것을 의미한다.
따라서 보낸 데이터가 충돌이 일어나서 제대로 보내지지 않았다면, ACK는 절대 오지 않는다.
위 프로시져에서 사용자가 정해주는 값은 $K_{max}$ 이다.
$K_{max}$ 는 데이터를 보내는 것을 최대 몇번까지 시도하게 할건지를 의미한다.
따라서 각 station이 데이터를 보낸 시도 횟수를 $K$ 라고 할 때, $K > K_{max}$ 인 경우 보내는 것을 중단(Abort)한다.
데이터가 보내질 때, 걸리는 시간을 propagation time이라고 한다.
위에서는 $T_p$ 라고 표시했고, 이 시간은 편도일때만 계산하므로 ACK가 올때까지 걸리는 시간은 최소 $2 \cdot T_p$ 이다.
데이터가 $2 \cdot T_p$ 만큼 기다렸는데도 오지 않았다면, $K = K+1$ 이 된다.
데이터 보내는 것을 실패했을때, 일정시간 대기하게 된다.
이때 대기 시간은 랜덤하게 정해야한다.
모두 같은 시간을 대기하게 되면, 한번 충돌난 데이터들은 이후에도 다시 충돌하게 된다.
따라서 이 랜덤한 값 $R$ 은 $0 \leq R \leq 2^{K}-1$ 이다.
잘 보면 $R$ 의 최대값이 $K$, 즉 데이터를 보내려고 시도한 횟수에 비례하게 되는데, 충돌이 여러번 나면 대기 시간이 계속 길어진다고 보면 된다.
이렇게 정한 $R$ 값과 전파 시간(Propagation time, $T_p$) 혹은 평균 전송 시간(Average transmission time, $T_{tr}$)과 곱하면, 대기시간(Backoff time, $T_B$)가 된다.
Vulnerable time

우리가 특정 frame을 보낸다고 할때, 보내는 시점 $t$ 를 기준으로 충돌이 날 가능성이 높은 쉬운(Vulnerable) 시간은 과연 어느정도일까?
위 그림에서 기준은 B이다.
ALOHA는 우리가 특정 frame을 보낼때
Frame A : 이미 medium이 사용중인 경우
Frame C : 보내고 있는 도중에 누군가 데이터를 보내려는 경우
를 고려하지 않는다.
전송 시간을 $T_{fr}$ 이라고 하자.
우리가 $t$ 라는 시점에 B라는 frame을 보낸다면, $t$를 기준으로
1. $t-T_{fr}$ : 이미 medium이 사용중일 수 있는 시간
2. $t+T_{fr}$ : 내가 medium을 사용중인데 누군가 medium에 접근할 수 있는 시간
이 충돌나기 딱 좋은 시간이다.
이를 취약 시간(Vulnerable time)이라고 하며, ALOHA의 경우 $2 \cdot T_{fr}$ 이 된다.
Slotted ALOHA
Slotted ALOHA 방식은 전송 시간($T_{fr}$) 단위로 시간을 나누고, 나눠진 시간대를 slot이라고 한다.
그리고 데이터는 slot이 시작하는 시간대에서만 데이터를 전송할 수 있다.

보면 각 slot의 시작부분에서 데이터를 보내는 것을 확인할 수 있다.
이게 그냥 ALOHA 방식이랑 다른점이 무엇일까?
특정 데이터를 보내는 시점을 $t$ 라고 할 때, 그냥 ALOHA는 $t-T_{fr}$ 과 $t+T_{fr}$ 인 부분이 충돌에 취약한 시간대로 정했었다.(애매하게 전송이 겹칠 수 있음)
Slotted ALOHA는 slot단위(길이는 전송 시간과 같다, 전송시간 = $T_{fr}$)로 나누어져 있기 때문에, $t$ 시점이 아니라면 medium이 사용되지 않는다는 것을 보장할 수 있다.(완벽하게 전송이 겹치는 경우만 있음)
반대로 말하면, 오직 $t$ 시점에서만 충돌이 일어난다는 것을 알 수 있다.
이는 vulnerable time이 $T_{fr}$ 이라는 말과 같다.
Carrier Sense Multiple Access (CSMA)
ALOHA는 충돌이 일어날 가능성이 너무 높았다.
따라서 충돌을 줄이기 위해 고안된 것이 CSMA (Carrier Sense Multiple Access) 이다.
데이터를 보내기 전에 medium을 검사해서, 아무도 보내지 않다고 판단하면 데이터를 보낸다.
이를 "sense before transmit" 또는 "listen before talk" 라고 한다.

위 그림은 특정 station이 데이터를 보내면서 medium을 사용하는 것을 시각화 한 것이다.

먼저 B는 $t_1$ 에서 데이터를 보내기 시작해서 위에 표시한 시간까지 보낸다.

또한 medium은 공유되므로 B랑 연결된 모든 station에게 같은 속도로 데이터가 전송된다.
즉, B가 데이터의 목적지로 정해둔 station이 있더라도 모든 station이 데이터를 전송받는다.

따라서 B와 C가 medium을 사용하는 것을 위와같이 나타낼 수 있는 것이다.
C는 B가 medium에 접근해서 데이터를 보내고 있더라도 전파 시간(propagation time)으로 인해 C한테 데이터가 늦게 도착하고 있다.
따라서 C는 아무도 medium을 사용하고 있다고 판단하지 않으며, $t_2$ 에 데이터를 보내기 시작한다.

C가 보내는 데이터도 마찬가지로 전파 시간이 존재하고, 위에 표시한 부분에서 충돌이 발생한다.
다시 맨 위의 그림을 보면, 회색으로 표시된 부분은 충돌이 일어나는 영역을 보여준다는 것을 알 수 있다.
Vulnerable time

위에서 확인했듯, medium이 사용중이라는 것을 각 station이 알 수 있으려면 전파 시간만큼 시간이 흘러야한다.
따라서 CSMA 방식의 vulnerable time은 전파 시간(propagation time)과 같다는 것을 알 수 있다.
Persistence Methods
이제 medium을 어떤식으로 확인(sense)하고 데이터를 보내는 지를 알아보자.

첫번째로 1-persistent는 계속 medium을 확인하다가, medium이 사용중이지 않을 때(idle 할때) 데이터를 보낸다.
- Ethernet에서 이 방식을 사용한다.

이에 대한 flow diagram은 위와 같이 매우 간단하다.

두번째는 nonpersistent 로 확인했을때 medium이 사용중(Busy)이라면, random한 시간동안 대기한 후 다시 확인하는 방법이다.

이에 대한 flow diagram도 딱히.. 복잡하지 않다.
Medium이 사용되지 않는다면, 랜덤한 시간동안 기다린 후, 데이터를 보낸다.


세 번째는 p-persistent로 1-persistent랑 nonpersistent를 섞어놓은 느낌이다.
먼저 medium을 1-persistent와 같이 계속 확인하고, 아무도 사용하지 않는다면 랜덤한 값($R$)을 생성한다.
위에서 $p$라는 값은 임의의 확률로 네트워크를 구성할때 정해지는 값이다.
이 $R < p$인 경우에만 데이터를 보내게 된다.
만약 반대로 $R \ge p$ 라면 Time slot을 기다린 후, medium을 체크한다.
- 만약 medium이 idle 상태라면, 랜덤한 값을 생성하는 과정으로 돌아간다.
- 만약 medium이 busy상태라면, back-off process(대기를 위한 프로세스)를 실행한다.
특정 시간 대기하도록 하는 부분이 nonpersistent와 비슷하다고 할 수 있다.
CSMA/CD (Carrier Sense Multiple Access with Collision Detection)
CSMA 방식을 생각해보면, medium을 체크(Carrier Sensing)해서 충돌을 최소화 한다고만 했지 충돌났을때의 동작은 정의되지 않았다.
CSMA/CD 방식은 충돌이 일어났을때, 어떻게 동작해야할지도 같이 정한다.

위 그림을 잘 보면, A에서 출발한 검정색 선과 C에서 출발한 빨간색 선이 교차하는 지점이 있다.
이 부분이 충돌(Collision)이 발생한 지점이 된다.
위에서 말했듯, C는 A의 데이터가 도착하지 않으면 medium이 사용중이라는 것을 알지 못한다.
따라서 persistent 방법을 사용하더라도 충돌을 최소화 할 수는 있지만, 충돌은 여전히 발생할 수 있다.
C는 데이터를 보내다가 A의 데이터가 C까지 오게되면 충돌이 일어났다는 것을 감지(Detect)하고 전송을 멈춘다(Abort).
반면 A는 아직 C의 데이터와 충돌이 일어났다는 것을 알지 못한다.
아직 C의 데이터가 A까지 도달하지 않았기 때문이다.

위 flow diagram의 오른쪽 회색 박스 부분을 보면 이상하다고 느껴진다.
데이터를 보내고 끝나는게 아니라, 데이터를 보내는 중간에 충돌이 일어났는지 확인하고 있다.
ALOHA 방식은 데이터를 다 보내고 ACK를 받는 방식이었지만
위에서 보았듯 CSMA/CD 방식은 데이터를 보내는 중간에 충돌을 확인한다.
따라서 이 중간에 확인하는 과정이 flow diagram에 위와같은 방식으로 표현된것이다.
충돌이 났음을 감지했을때, Jamming signal을 보내는 부분이 있다.
Medium은 공유되니까 충돌이 났으면 모든 station들이 감지했을텐데, 굳이 jamming signal을 보낼 이유가 있나?
what's the usage of jamming signal in CSMA/CD?
Take the coxial cable for example, I already understand in CSMA/CD all stations use the same channel to transit data,and if two stations transit data at the same time,a collision occurs and once the
networkengineering.stackexchange.com
when two stations close to each other produce a collision, a station further away might not detect it due to the (short) signals not overlapping at its location.
위와 같이 설명하는 글을 찾았다.
너무 멀리있는 station은 충돌을 감지하지 못했을수도 있기 때문에 jamming signal을 한번 더 보낸다.
따라서 jamming signal을 받은 station은 지금 들어오는 데이터에 문제가 있음을 확인할 수 있다.
ALOHA 방식과의 차이점
CSMA/CD 방식의 flow diagram을 보면 ALOHA 방식과 비슷하다.
하지만 차이점이 존재하는데 다음과 같다.
1. Persistent method를 실행하는 process가 존재한다.
2. 한번에 데이터를 전부 보내는 ALOHA와는 달리, CSMA/CD는 중간에 계속 충돌을 확인한다.
3. Jamming signal을 사용하여 다른 station들도 충돌이 일어났음을 알린다.
상태에 따른 medium의 에너지 차이

- 데이터를 보내는 경우 : Busy인 경우
- 아무도 medium을 사용하지 않는경우 : Idle한 경우
- 충돌이 일어난 경우 : Collision
여기서 충돌이 일어난 경우 에너지가 busy인 경우보다 많이 발생한다.
따라서 medium을 공유하는 경우, 에너지 차이를 확인하여 충돌을 감지할 수 있다.
CSMA/CA (Carrier Sense Multiple Access with Collision Avoidance)
무선에서 사용되는 CSMA 방식이다.
무선이기 때문에 medium의 에너지 차이를 알 수가 없게된다.
즉, 충돌이 일어났는지 아닌지를 확인할 방법이 없게된다.
따라서 충돌을 피하기 위해 세가지 방법을 사용하는데 아래와 같다.
1. Interframe space
2. Contention window
3. Acknowledgments
하나씩 알아보자.

기본적으로 carrier sensing하는 부분이 존재한다.
그리고 interframe space(IFS)만큼 대기한다.
즉, 아무리 medium으로 들어오는 데이터가 없더라도 한번더 의심하는 방식이다.
IFS는 데이터를 보내기 전, 잠시 대기하는 시간으로 이해하자.

랜덤한 값을 정하는 부분이 바로 contention window 이다.
K에 대한 설명은 ALOHA 방식과 같기 때문에 추가적으로 하지 않겠다.
랜덤한 값을 $0 \leq R \leq 2^K -1$ 에서 뽑는다.
그리고 contention window에서 $R$값에 해당하는 slot을 사용하게 된다.
즉, 해당 slot으로 시간이 흐를때까지 기다렸다가 데이터를 보낸다.
이는 IFS 만큼 기다리고, 또 한번 더 기다리는 방식으로 이해할 수 있고 p-persistent 방식과 유사함을 느낄 수 있다.
다음으로 request to send(RTS)를 전송하는데, 이는 목적지에 해당하는 station에게 데이터를 보내도 되는지 확인하는 frame이다.
이후 타이머를 동작시키고, clear to send(CTS)를 기다린다.
CTS는 RTS를 받은 station이 데이터를 보내도 된다고 알리는 frame이다.
만약 time-out이 될때까지 CTS가 오지 않는다면, 대기하거나 보내지 않도록 한다.
CTS가 time-out 전에 도착했다면, 다시 IFS만큼 기다리고 데이터를 전송한다.
그리고 익숙하겠지만 타이머를 동작시킨다음 ACK를 기다린다.
ACK가 time-out 이전에 들어오지 않았다면, 대기하거나 보내지 않도록 한다.
ACK가 time-out 이전에 들어왔다면, 전송에 성공했다는 것을 알 수 있다.

위에서 carrier sensing 한 다음, IFS만큼 기다리고 contention window 과정을 거쳤었다.
그때의 대기시간을 DCF interframe space(DIFS)라고 부른다.
RTS를 보낸 후, 목적지 station은 short interframe space(SIFS, DIFS 보다 더 적은 시간을 갖는다) 만큼 기다린다.
이후 CTS를 보내고, 출발지 station은 SIFS만큼 기다린 후, 데이터를 전송한다.
목적지 station은 데이터가 전부 도착한 후, SIFS만큼 기다린 후 ACK를 보내게 된다.
이때 CTS에는 얼만큼의 시간동안 데이터를 보낼지에 대한 정보가 들어있다.
따라서 위의 C와 D의 경우는 CTS에 명시된 시간만큼 데이터를 보내지 않는다.
위 그림에서 NAV(Network allocation vector)가 이를 나타냄을 알 수 있다.
Channelization protocols
Channel partition이라고도 불리는 이 방식은 가능한 대역폭을 다음과 같은 관점에서 공유한다고 가정한다.
1. 시간 (Time-division multiple access, TDMA)
2. 주파수 (Frequency-division multiple access, FDMA)
3. 코드 (Code-division multiple access, CDMA)
각각에 대해 알아보자.
TDMA (Time-division multiple access,)

TDMA는 위 그림과 같이 각 station이 time slot을 할당받아 사용하는 방식이다.
따라서 station들은 정해진 시간대에만 데이터를 전송할 수 있고, 사용가능한 대역폭을 모두 사용할 수 있다.
FDMA (Frequency-division multiple access)

FDMA는 대역폭을 station들이 나누어서 사용하는 방식이다.
TDMA와는 달리 모든 대역폭을 사용할 수는 없지만, 연속해서 계속 보낼 수 있다는 장점이 있다.
CDMA (Code-division multiple access)

CDMA 방식은 FDMA와는 다르게 채널이 한 개이며, TDMA와는 다르게 time slot 없이 동시에 여러 station들이 데이터를 보낼 수 있게한다.

위 그림에서 $d_n$ 은 station들이 보낼 하나의 비트이다.
비트 값이 0이면 -1, 1이면 1, 보낼게 없으면 0을 갖는다.

$c_n$ 은 chip sequence 라고 부르며, medium을 사용하는 station의 개수만큼의 길이를 같는 배열이다.
값은 아무렇게나 정해지는 게 아니라 1과 -1로 이루어져 있어야하고, 미리 정해진 배열들이 할당된다.
CDMA는 맨 위 그림에서 볼 수 있듯 다음과 같은 절차가 존재한다.
1. 각 station은 본인이 보낼 데이터 비트 $d$ 와 chip sequence $c$ 를 곱한다.
예를들어 -1과 [1, -1, 1, -1] 을 곱하면, [-1, 1, -1, 1]이 된다.
2. 최종적으로 각 station에서 처리된 $d \cdot c$ 들이 더해져서 보내진다.
[-1, -1, -1, -1], [-1, 1, -1, 1], [0, 0, 0, 0], [1, -1, -1, 1] 을 더하면, [-1, -1, -3, 1] 이 된다.
Chip sequence들은 다음과 같은 특징을 가지고 있다.
1. 똑같은 chip sequence를 곱한 결과는 항상 모든 값이 1인 sequence가 된다.
2. 서로 다른 값을 가진 chip sequence들끼리 곱해지면, 2개의 +1 과 2개의 -1이 존재하는 sequence가 된다.
이런 특징은 channel을 통해 전송되는 데이터를 decoding할때 사용된다.
어떻게 전송받은 데이터에서 어떤 station이 어떤 값을 보냈는지 decoding 할 수 있을까?

전송받은 데이터와 특정 station이 가진 chip sequence를 곱하면 된다.
예를들어 위 그림에서 station 2가 어떤 값을 보냈는지 decoding을 수행한다고 해보자.
전송받은 데이터는 항상 $d_1 \cdot c_1 + d_2 \cdot c_2 + d_3 \cdot c_3 + d_4 \cdot c_4$ 이다.
여기에 station 2의 chip seqence를 곱하면 다음과 같다.
$d_1 \cdot c_1 \cdot c_2 +$
$d_2 \cdot c_2 \cdot c_2 +$
$d_3 \cdot c_3 \cdot c_2 +$
$d_4 \cdot c_4 \cdot c_2$
이제 각 항을 계산해보자.
이때 각 항에서 계산된 sequence의 모든 값을 더해서 나타내면 chip sequence의 특징에 의해 다음과 같이 나타난다.
$d_2 \cdot c_2 \cdot c_2 = [d_2, d_2, d_2, d_2] = 4 \cdot d_2 = -4$ 이고, 나머지는 모두 0이 된다.
위에서 말했듯, 같은 chip sequence끼리 곱하면 모두 1인 sequence가 나오고 다른 chip sequence끼리 곱하면 +1이 두번 -1이 두번 나오는 sequence가 나오기 때문이다.
이때 4라는 값은 station의 개수와 같다는 것을 알 수 있다.
따라서 station 2가 보낸 값은 $\frac{-4}{4} = -1$ 이 된다.
이렇게 각 station이 가진 chip sequence들을 통해 decoding을 수행할 수 있게된다.
'CS > 데이터 통신' 카테고리의 다른 글
| [데이터 통신] Data Link Control(DLC) (4) | 2023.05.19 |
|---|---|
| [데이터 통신] Error Detection 과 Correction (4) | 2023.04.19 |
| [데이터 통신] Data-link Layer 집중탐구 (0) | 2023.04.18 |
| [데이터 통신] Spread Spectrum (0) | 2023.04.12 |
| [데이터 통신] Multiplexing (0) | 2023.04.12 |